Revolt: Collaborative Crowdsourcing for Labeling Machine Learning Datasets
TLDRRevolt eliminates the burden of creating detailed label guidelines by harnessing crowd disagreements to identify ambiguous concepts and create rich structures (groups of semantically related items) for post-hoc label decisions.
How do people cite this paper?
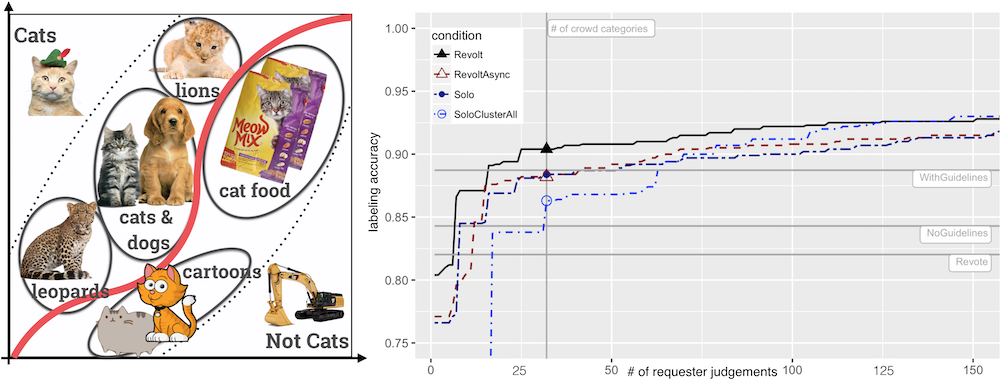
(generated 5 months ago)Revolt's collaborative crowdsourcing workflow and its treatment of annotator disagreement as a valuable signal rather than noise have influenced research across several areas: its Vote-Explain-Categorize pipeline has been adopted and extended by systems exploring structured deliberation and worker interaction in crowdsourcing tasks, skip-based self-filtering annotation, and iterative guideline refinement; its insight that ambiguous or incomplete labeling guidelines lead to inconsistent labels — and that this ambiguity can be productively harnessed — has been referenced in studies on inter-rater disagreement modeling, subjective annotation tasks, and participatory approaches to value alignment; its post-hoc label grouping mechanism has informed work on flexible taxonomy construction and concept evolution during data labeling; and it is broadly cited as a representative crowdsourcing method for constructing ML training data in domains ranging from biomedical image analysis to audio annotation and knowledge graph population.